Any Joke's left in Belgium?
What I was wondering: are there still Joke’s born in Belgium?
Every time I pass by a colleague named Joke, I wonder. Let me explain:
Joke is quite regular Dutch first name for a girl. You pronounce it
[yo-ke], like blending ‘yoghurt’ and ‘kebab’ together and put the
accent on the ‘yo’. ‘Joke’ is just a diminutive form of Jo, kind of like
Jenny, Abby and Debby. No-one who grew up speaking Dutch would bat an
eye to hear about someone named Joke, but everyone else on this planet
probably would.
Considering how this name sounds in English and
how important English as a language has become in our daily life and
business world, I wondered whether there were any parents that would
still name their daughter Joke…
Data source
I found everything I needed on (this
website)
from the Belgian government.
Data
The data came in the form of two excel files, one for girls and one for
boys. Every file contains a sheet for every year (1995-2016), and then
numbers per region per name (see picture below). Not ideal, but nothing
that some cleaning up can’t handle.
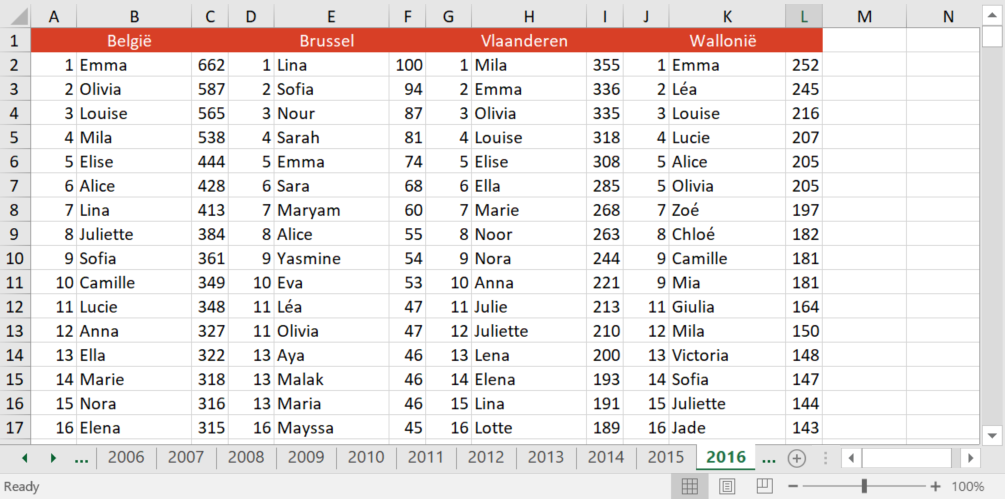
Two quick notes before I move on:
- The original data file contains the numbers for Belgium as a whole, and for every region seperate (Flanders, Wallonia and Brussels). Only the Belgian data is pulled out into the clean file right now.
- No names below 5 occurences are present in the database, presumably
for privacy reasons.
Cleaning data
Starting by loading the packages needed:
library(readxl)
library(tidyr)
library(dplyr)
library(ggplot2)
Given that both files contained many different sheets
representing the years, I started by creating a variable that would hold
all the sheetnames.
#Importing files
file_girls <- "First names girls 1995-2016.xls"
sheetnames_girls <- excel_sheets(file_girls) [1:22]
file_boys <- "First names boys 1995-2016.xls"
sheetnames_boys <- excel_sheets(file_girls) [1:22]
I wanted to build a function that would read all those sheets
and bind the data together. I first wrote the code for one sheet before
turning it into a function. At least then I know everything works the
way I want it to.
#Trial set to build up the function later on
input1995 <- read_excel(file, "1995")
data1995 <- input1995[,2:3]
data1995$Year <- 1995L
data1995$Region <- "Total Belgium"
Time to build the actual function, which:
- Reads a worksheet from the excel file
- Retains only column two and three which represents the names and number of occurences for total Belgium.
- Turns the sheetname into a variable called Year
- And adds a variable region “Total Belgium”
#A function that read a sheet(representing a year), and returns Total Belgium data
read_excelsheet <- function (file, sheetname) {
input <- read_excel(file, sheetname)
data <- input[,2:3]
data$Year <- as.integer(sheetname)
data$Region <- "Total Belgium"
return(data)
}
With the function read_excelsheet up and working, it’s time to
start reading in the data. I used a for loop to go through all the
sheetnames defined in sheetnames_girls and bind every new data to the
previous ones. Afterwards I did the exact same thing for the boys.
#Reading all sheets
data_g <- data.frame()
for (i in sheetnames_girls) {
data_g <- bind_rows(data_g, read_excelsheet(file_girls, i))
}
data_b <- data.frame()
for (i in sheetnames_boys) {
data_b <- bind_rows(data_b, read_excelsheet(file_boys, i))
}
Nearly there. I combined the girls and boys data, and did some
touching up by changing column names and changing their order.
#Combine girls and boys in 1 database
data_g$Gender <- "Girls"
data_b$Gender <- "Boys"
data <- data.frame(bind_rows(data_g, data_b))
#Renaming columns and clean-up
colnames(data)[1:2] <- c("Name", "Count")
data <- select(data, Region, Year, Gender, Name, Count)
rm(data_b)
rm(data_g)
Cleaning is all done now! For anyone who does not want to go
through the cleaning, I added a cleaned file via write.csv into (my
github
repository).
The cleaned data now looks as following:
## Region Year Gender Name Count
## 1 Total Belgium 1995 Girls Laura 1484
## 2 Total Belgium 1995 Girls Sarah 914
## 3 Total Belgium 1995 Girls Julie 865
## 4 Total Belgium 1995 Girls Charlotte 773
## 5 Total Belgium 1995 Girls Marie 726
## 6 Total Belgium 1995 Girls Manon 539
Searching for Joke
With the cleaning done, it’s time to find out whether there are any Joke’s left in Belgium.
#Searching for Joke
Joke <- filter(data, Name=="Joke")
Joke %>%
group_by (Year) %>%
summarise(Count)
## # A tibble: 18 x 2
## Year Count
## <int> <dbl>
## 1 1995 102
## 2 1996 91
## 3 1997 87
## 4 1998 92
## 5 1999 81
## 6 2000 65
## 7 2001 61
## 8 2002 58
## 9 2003 46
## 10 2004 34
## 11 2005 32
## 12 2006 26
## 13 2007 15
## 14 2008 16
## 15 2009 13
## 16 2010 19
## 17 2011 14
## 18 2012 9
It’s pretty obvious that the number of Joke’s has dropped significantly. The summary table above does not show any data for 2013-2016, so I will add zero’s manually to show in the graph below that we have data past 2012. Given that no data is present for names that are given less than 5 times, this might not be entirely correct though.
#Adding empty rows until 2016
Joke <- Joke %>%
rbind(list("Total Belgium", 2013, "Girls", "Joke", 0)) %>%
rbind(list("Total Belgium", 2014, "Girls", "Joke", 0)) %>%
rbind(list("Total Belgium", 2015, "Girls", "Joke", 0)) %>%
rbind(list("Total Belgium", 2016, "Girls", "Joke", 0))
The answer
In 1995 the world was not yet very global and about 100 Joke’s were born
that year, but since then it’s been decreasing year after year. The last
few years, it’s been less than 5 a year.

The previous plot does not show anything in how it compares to
other names though. So I made a second graph: Every grey line represents
a girls’ name, and Joke is in purple. It never was a hugely popular
name, but still far from being negligible either.
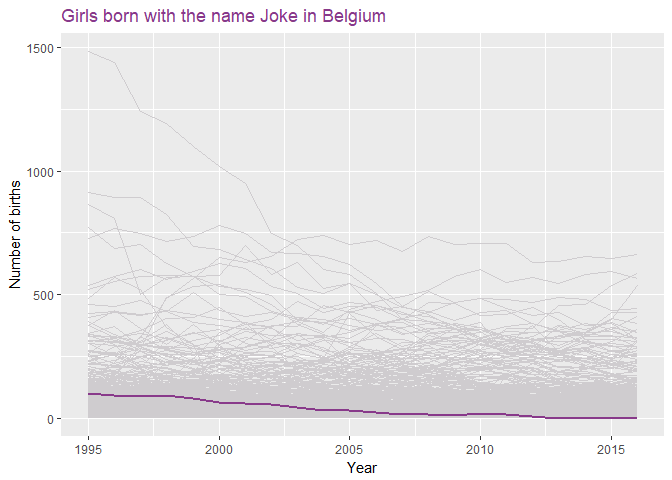
There are a lot of other interesting things in this database,
but I just want to highlight one other thing: there was one curve that
caught my eye because of it’s very abrupt demise.
Mathilde is the name
of the current Queen of Belgium. She became engaged to our crown prince
Filip back in 1999. Not everything royal starts a copycat movement - or
at least not in Belgium.

Link to github repository with code and data:
https://github.com/suzanbaert/2017_First-names-in-Belgium

